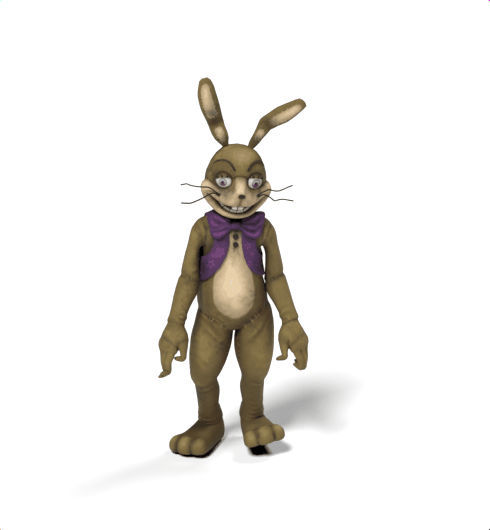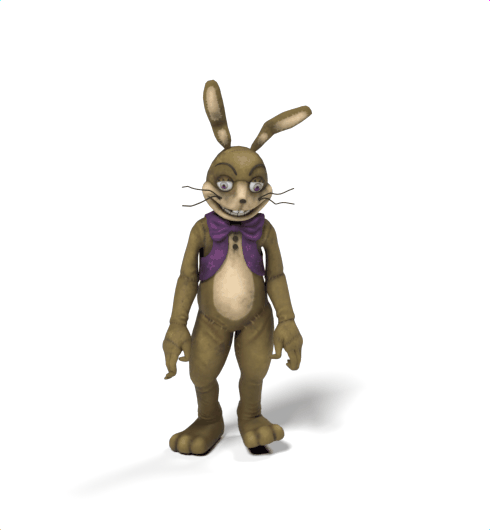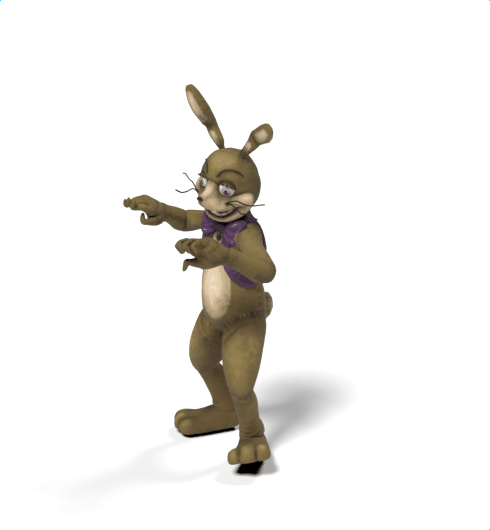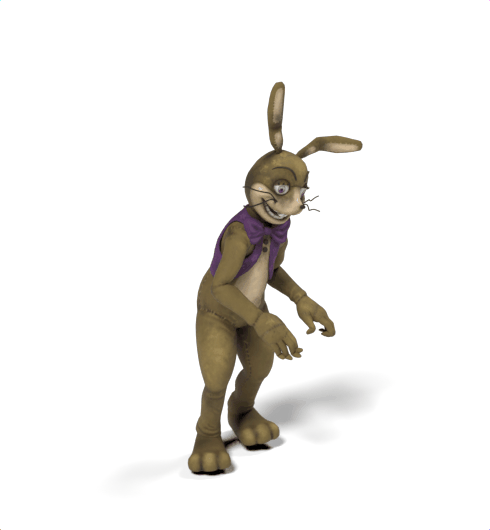SAMoR: Motion Modelling for Articulated Objects of Any Skeleton and Topology
1 Imperial College London ·
2 University of Tübingen, Tübingen AI Center
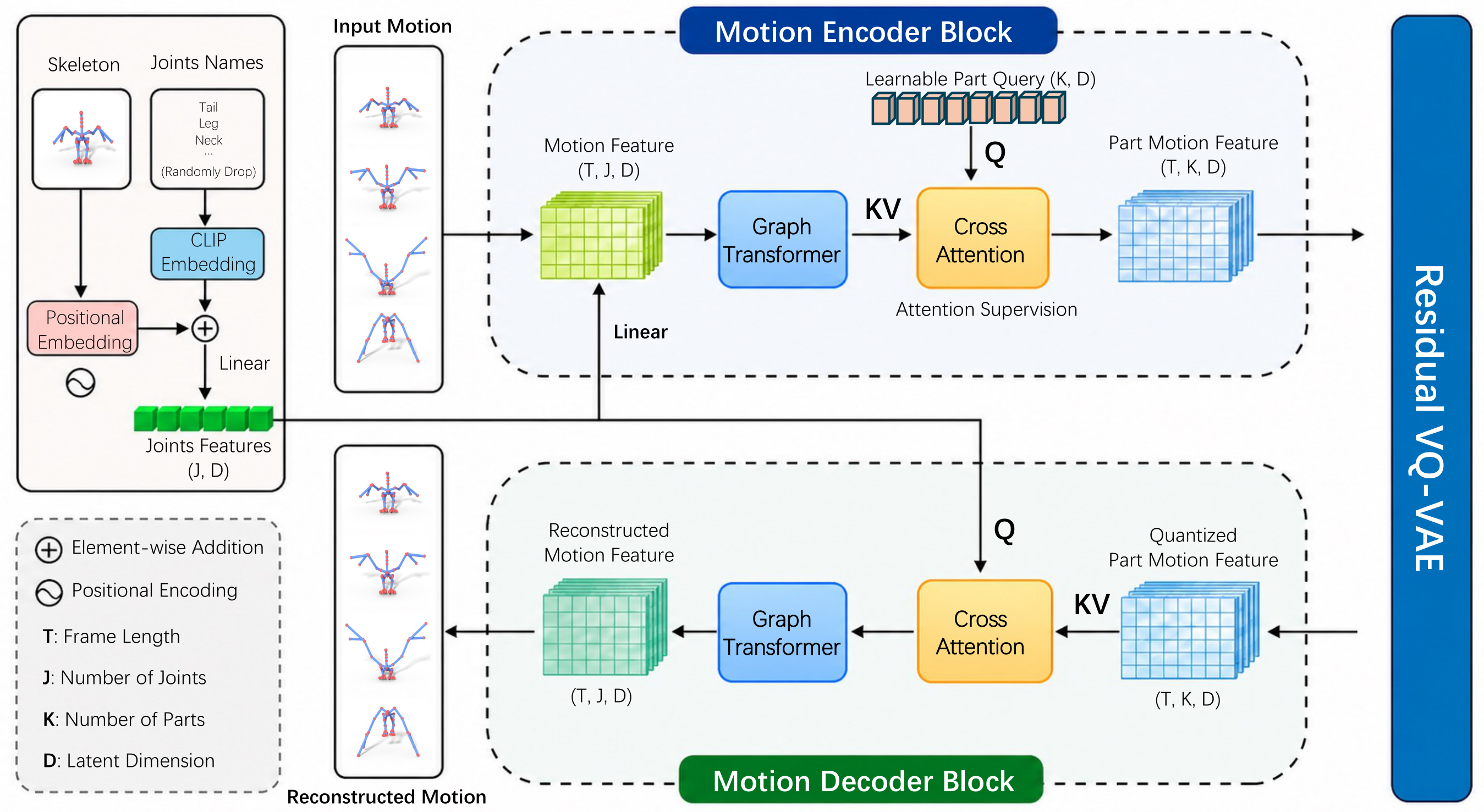
We introduce SAMoR (Skeleton-Aware Motion Representation for Articulated Objects), a cross-topology motion representation that encodes each motion segment as a small fixed number (K = 8) of part tokens shared across arbitrary skeletons. SAMoR processes per-joint motion features, kinematic graph structure, and joint-name embeddings with a graph-transformer encoder, then compresses the resulting heterogeneous per-joint features into part-level tokens via cross-attention pooling and residual vector quantization, yielding a discrete motion codebook shared across rigs. To prevent the part queries from collapsing into redundant global representations, we introduce a topology-agnostic attention supervision loss, combined with random joint-name dropout to prevent over-reliance on text labels; together these encourage the part tokens to cluster joints into functional groups from names, structure, and motion jointly.
End-to-end pipeline: an AI-generated photo is first lifted into an AI-generated mesh, then processed by an auto-rigging system to attach a skinned skeleton; SAMoR generates or transfers motion onto that rig; and LBS produces the final animation. Monster and Girl use text-conditioned generation; Octopus uses cross-topology motion transfer.







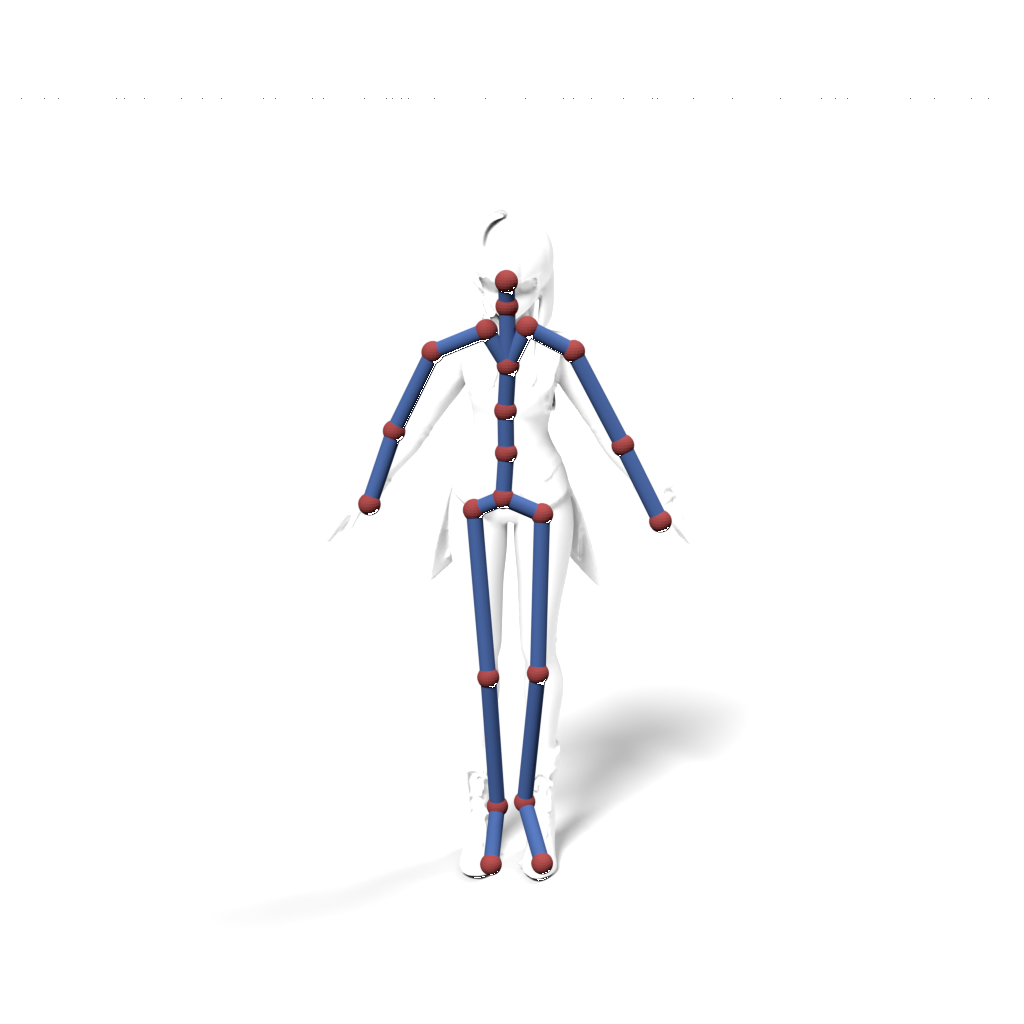







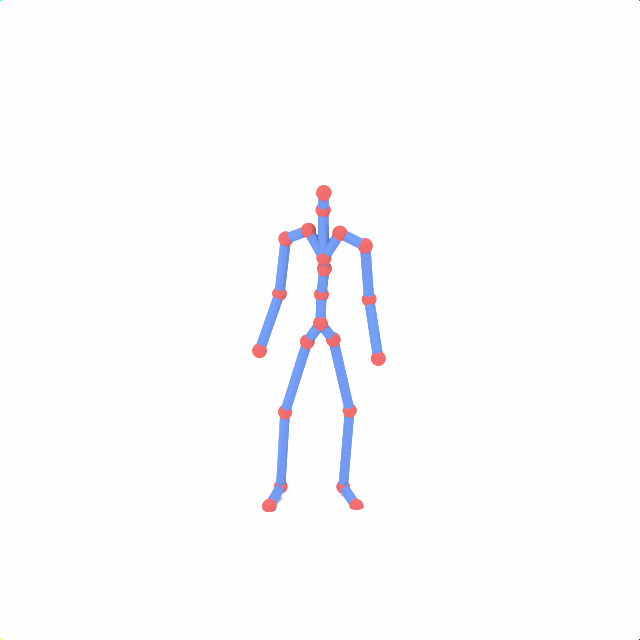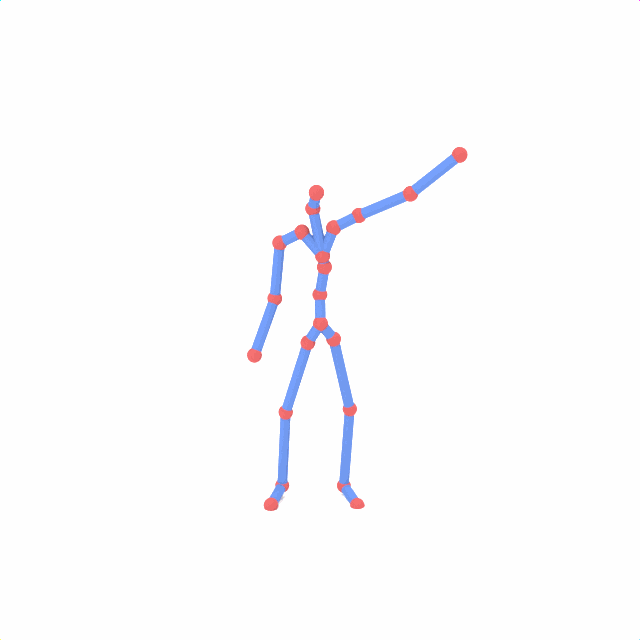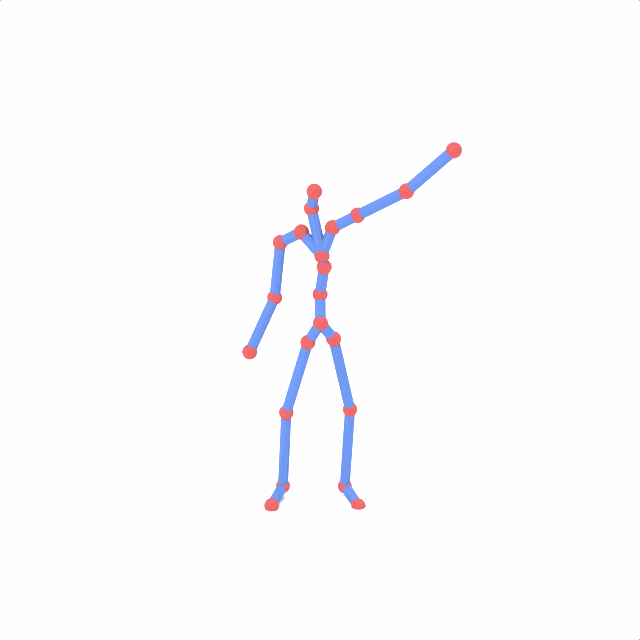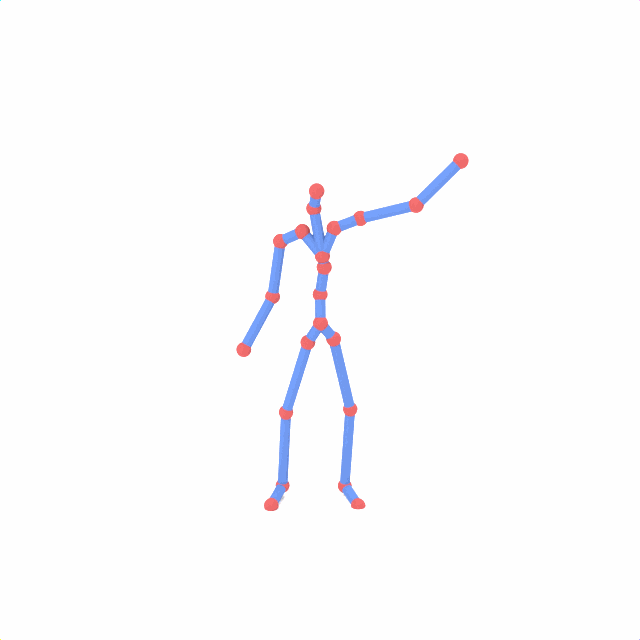


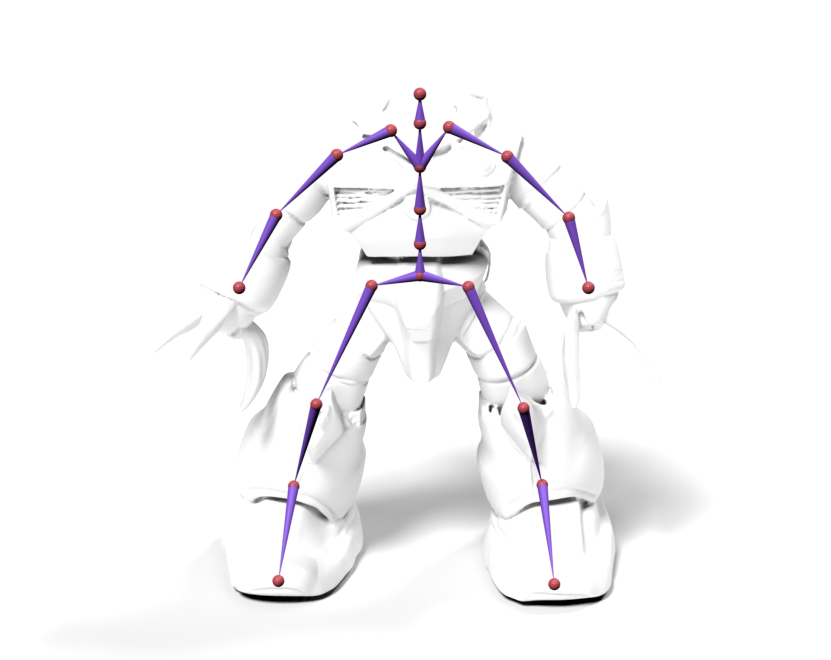


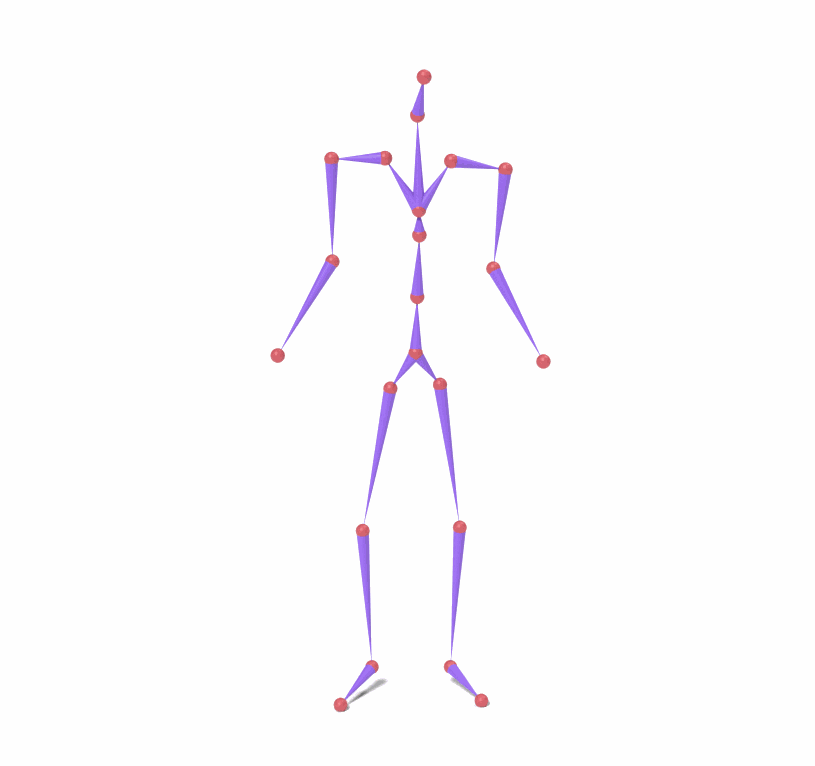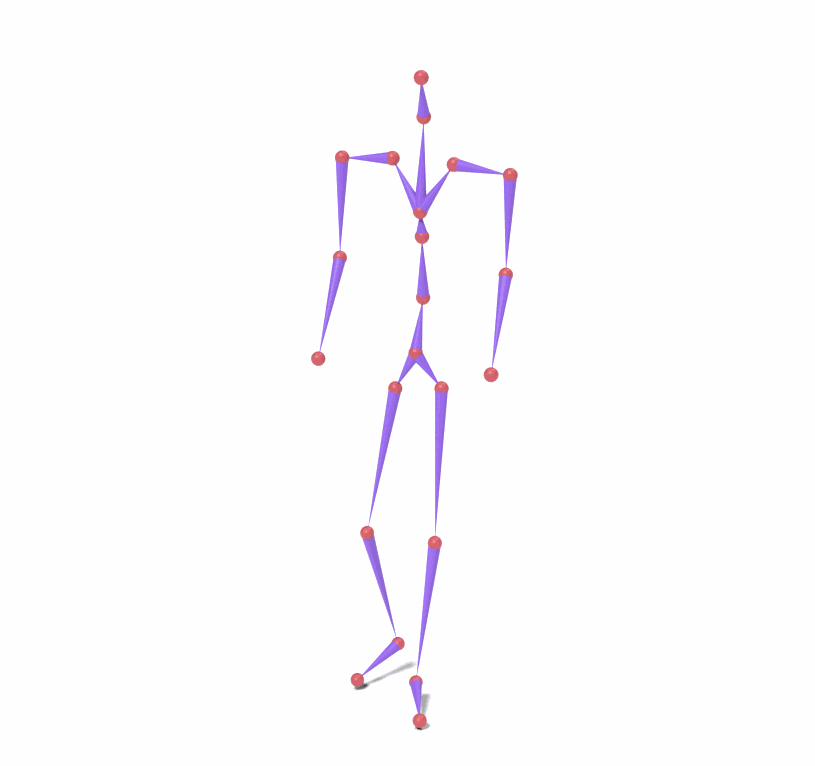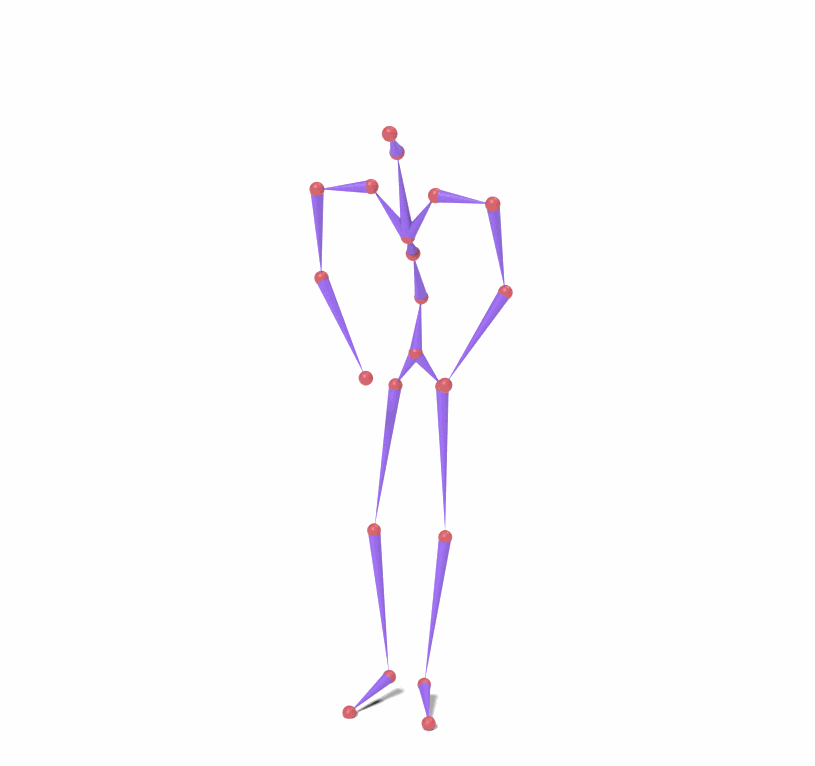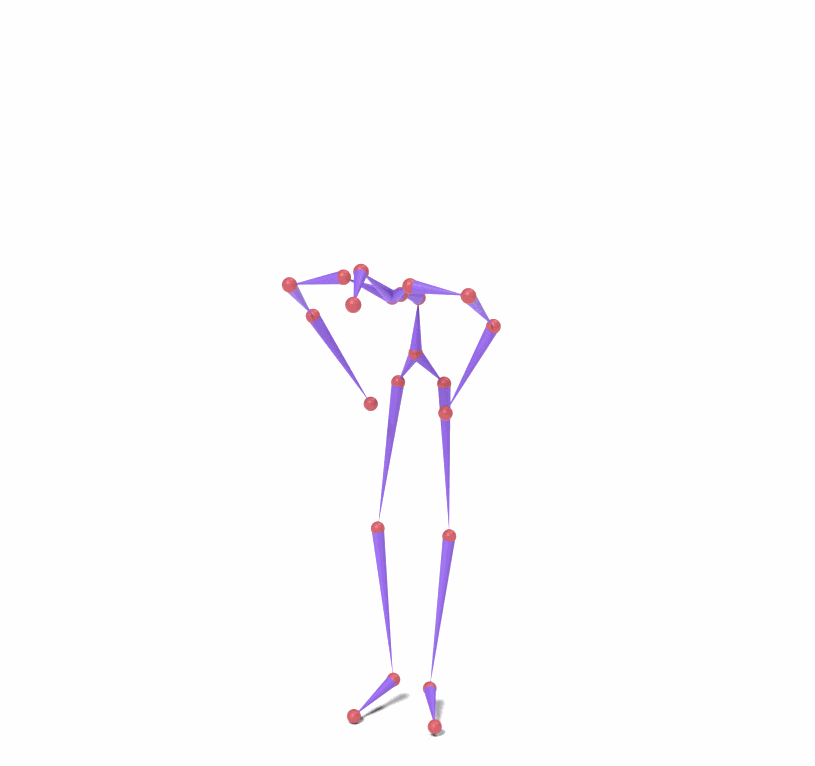
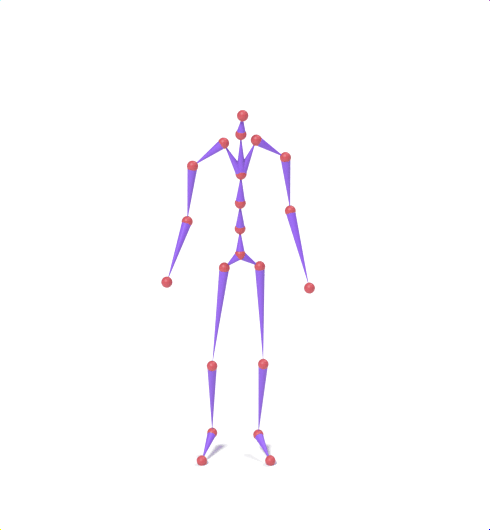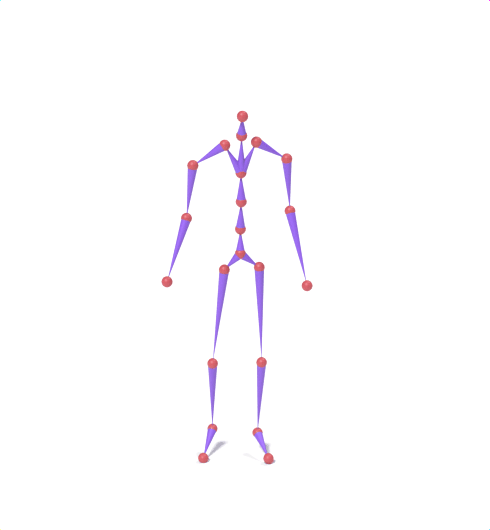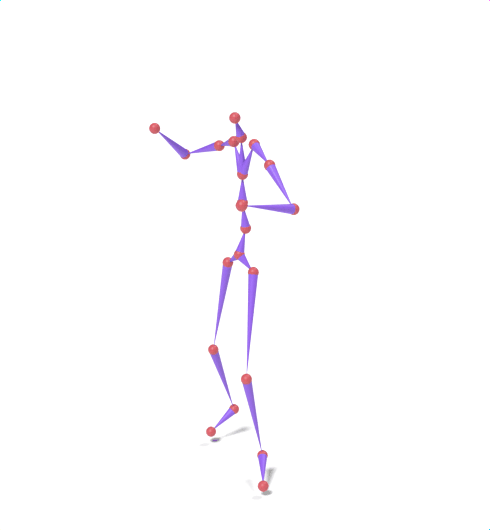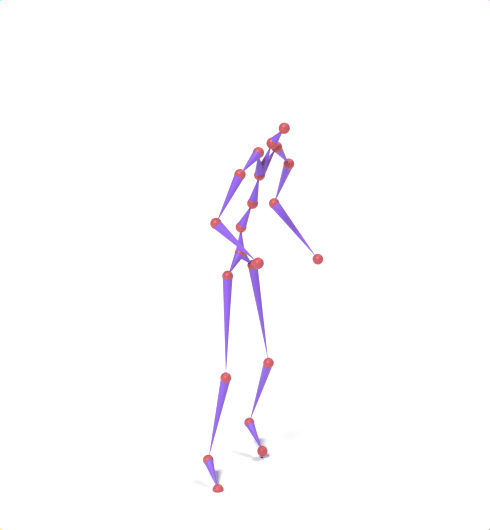
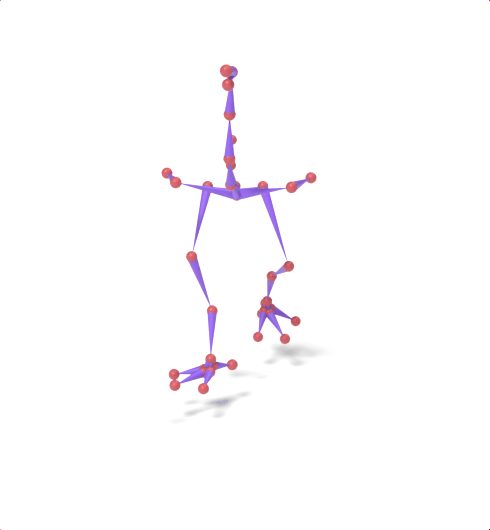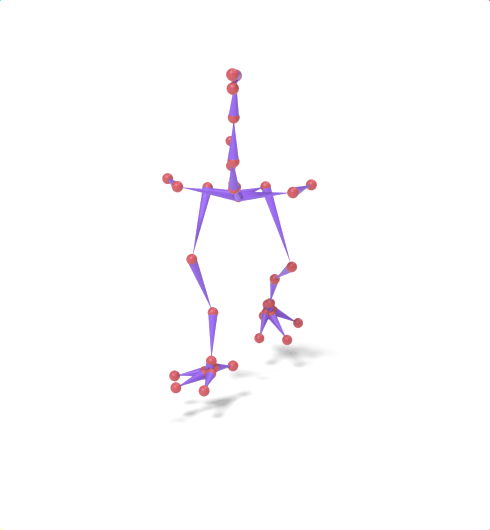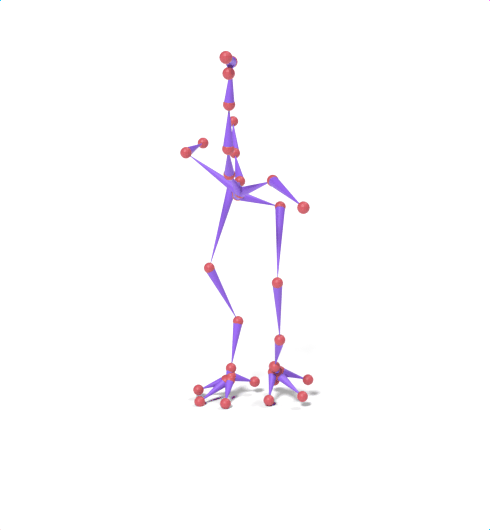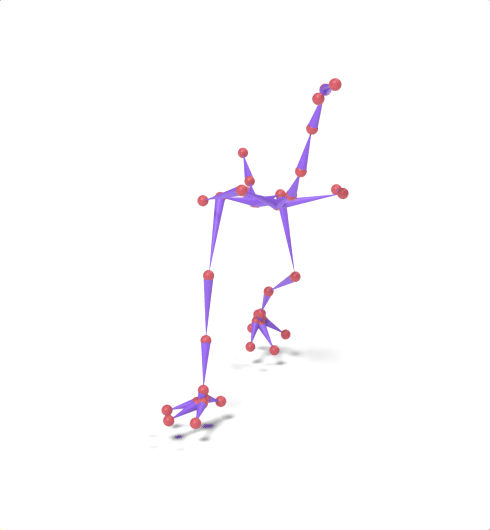
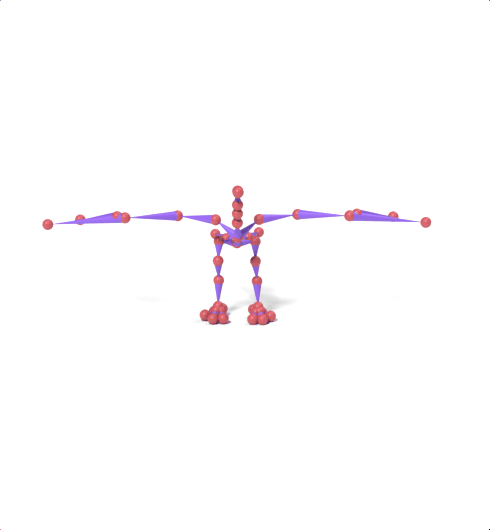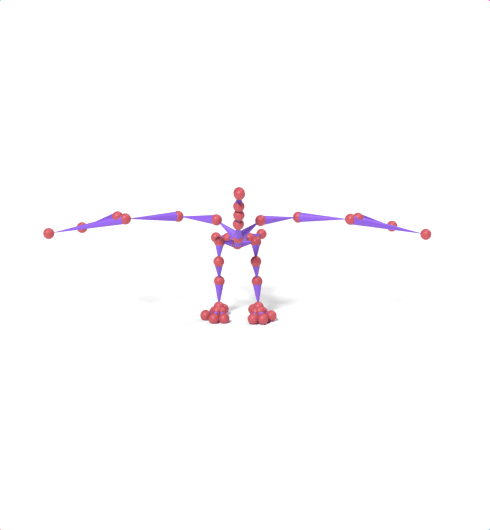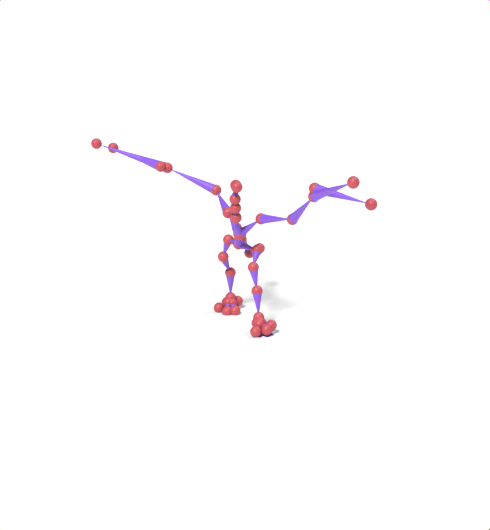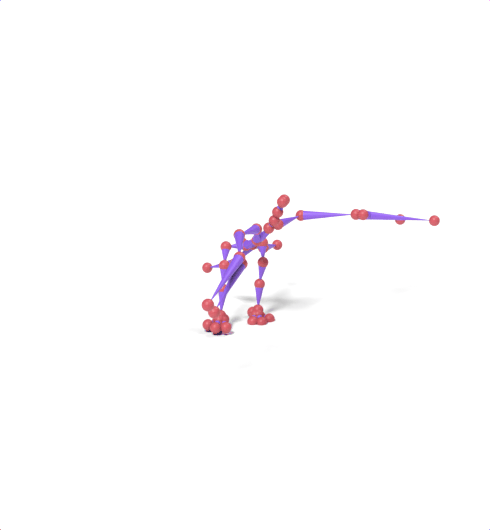
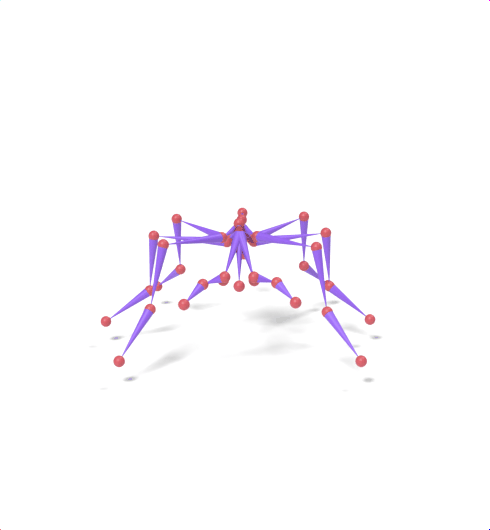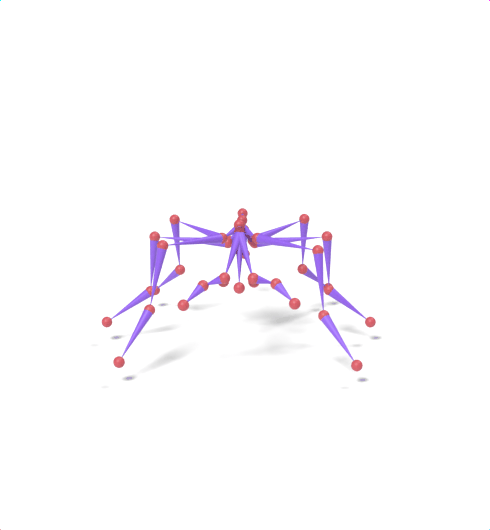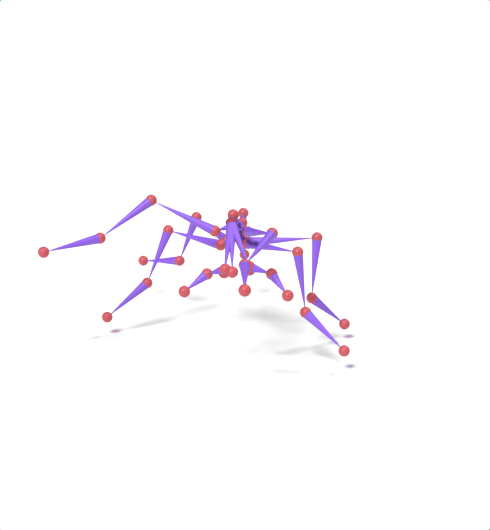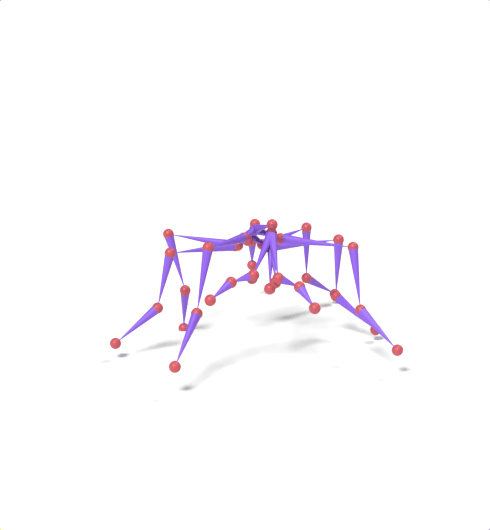
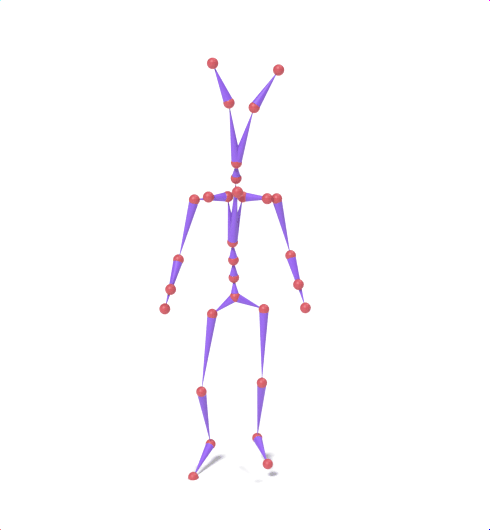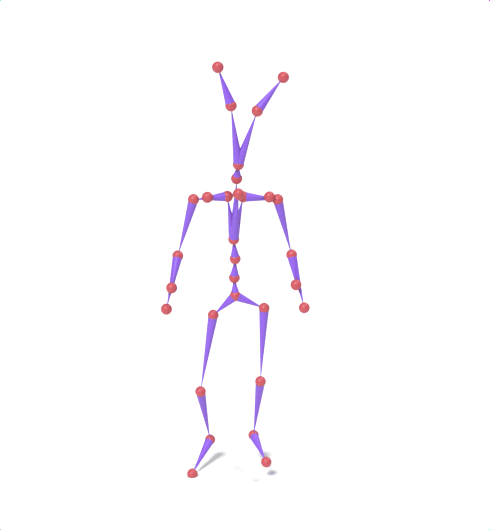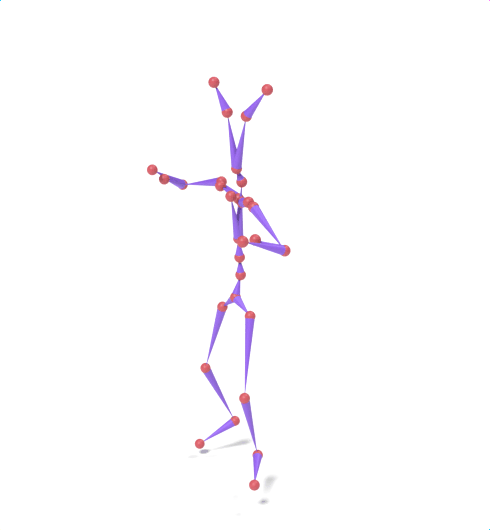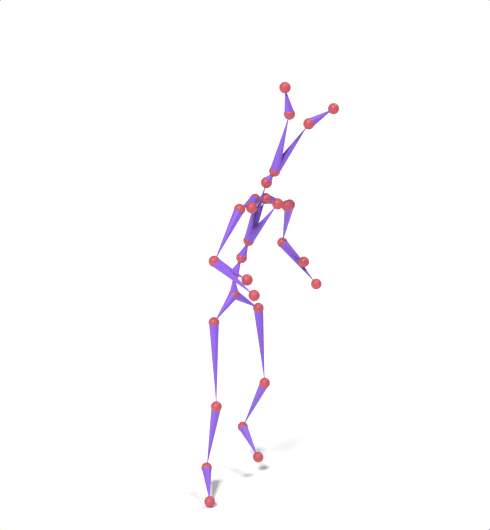
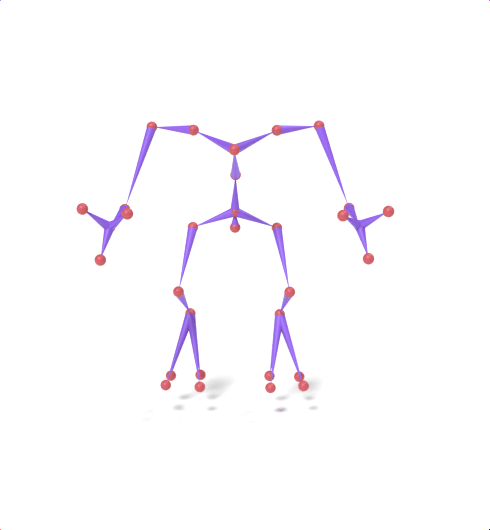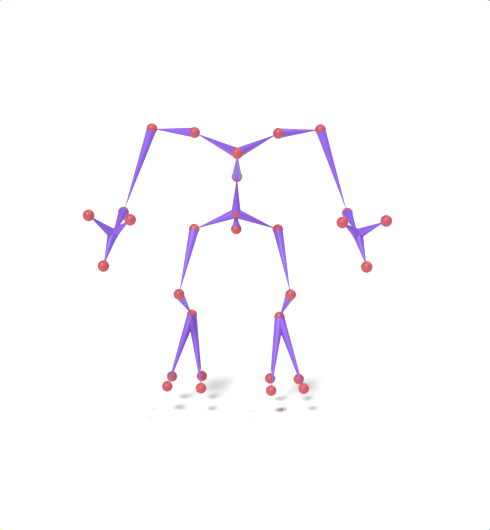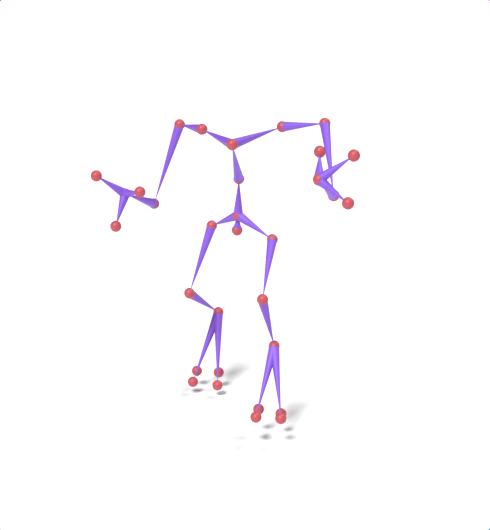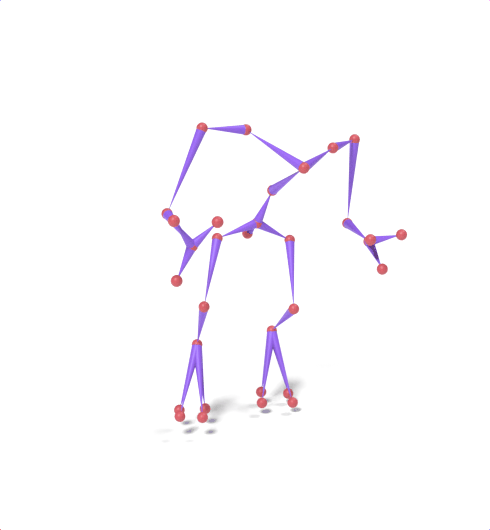
Source skeleton motion (left) decoded onto target skeleton (right) across diverse topology gaps. The one-source-to-many demo is shown above as the teaser.

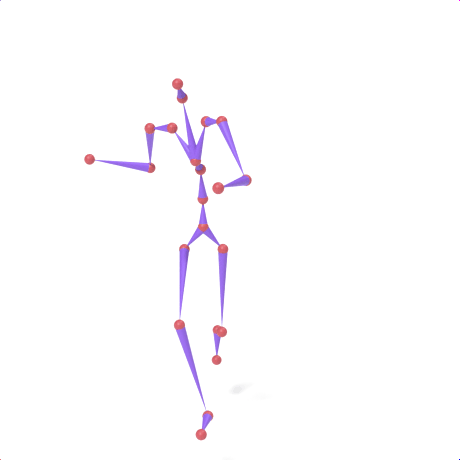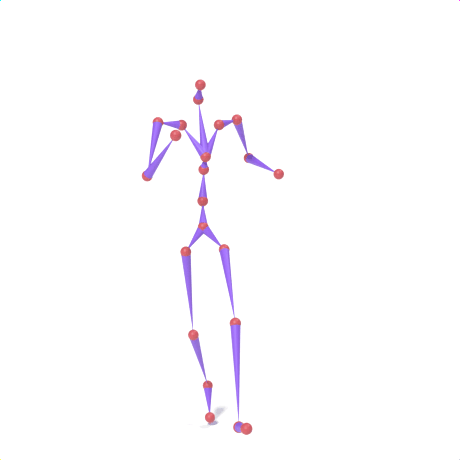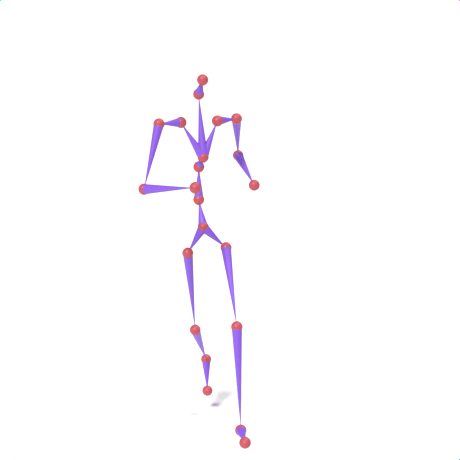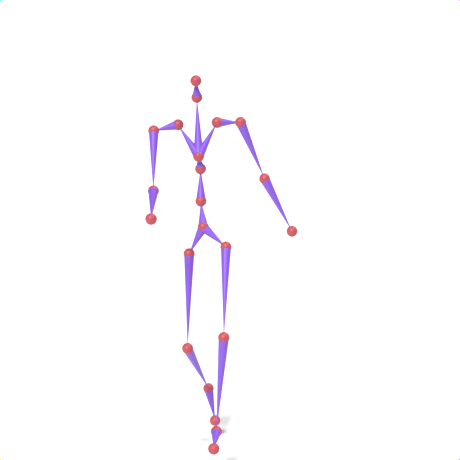

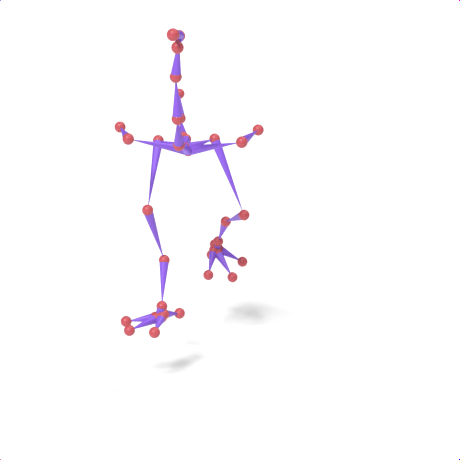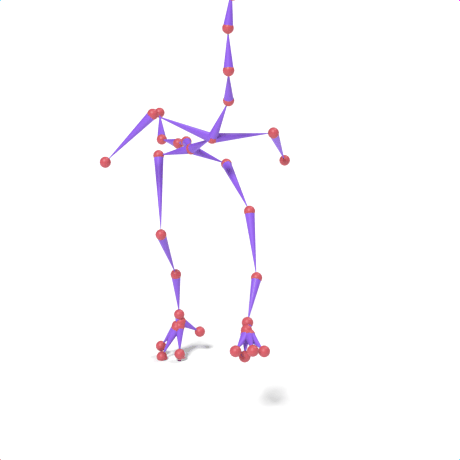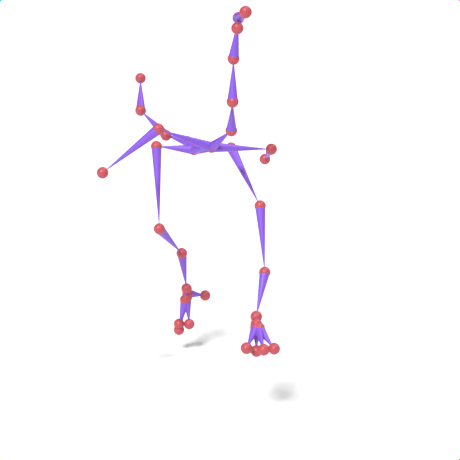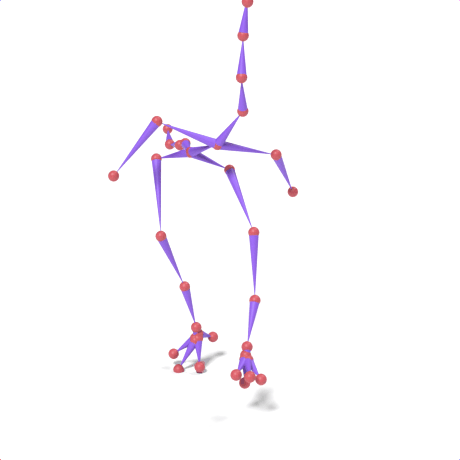

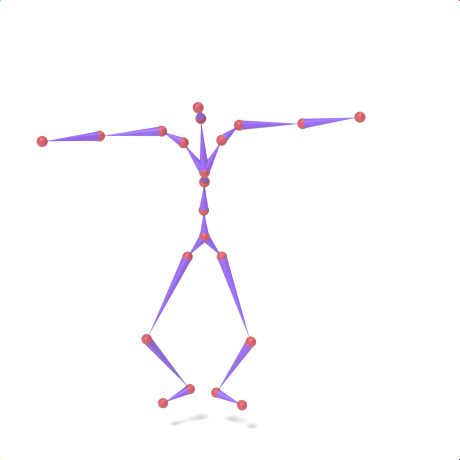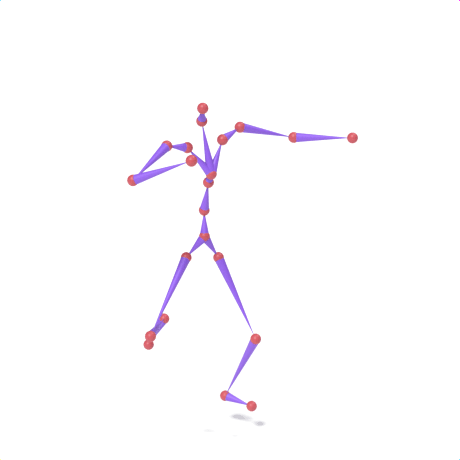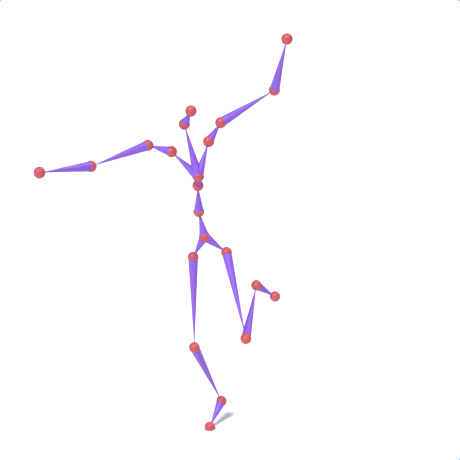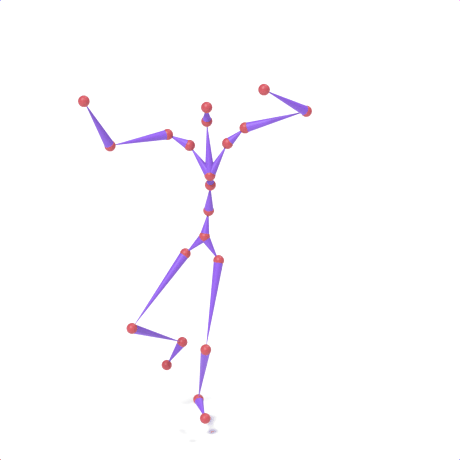

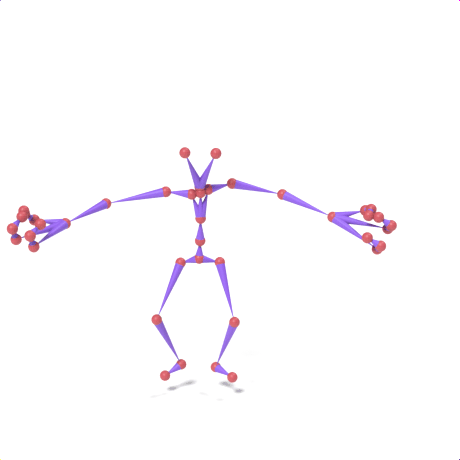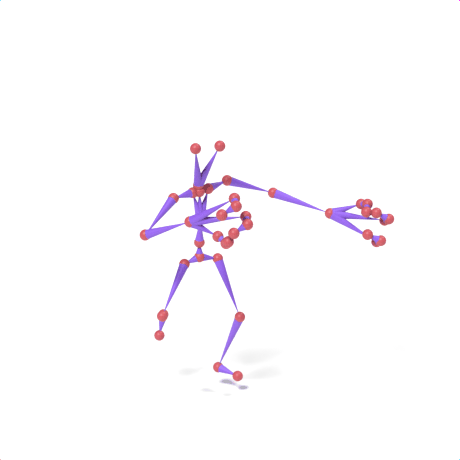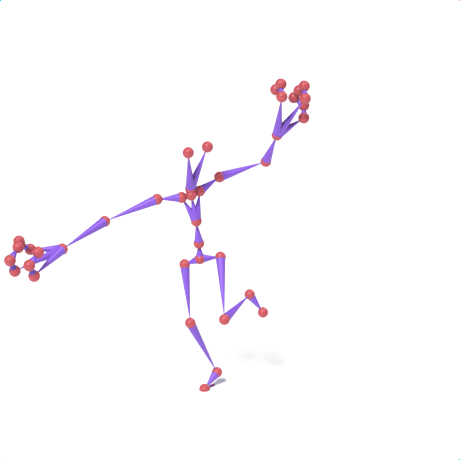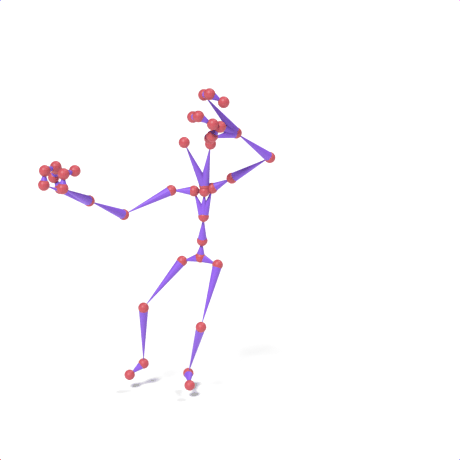


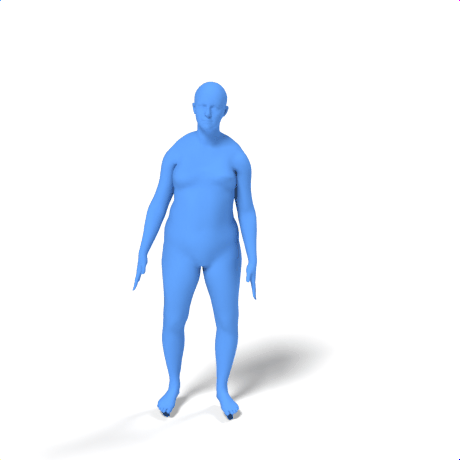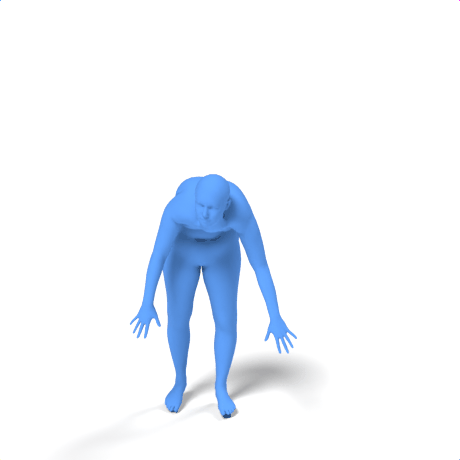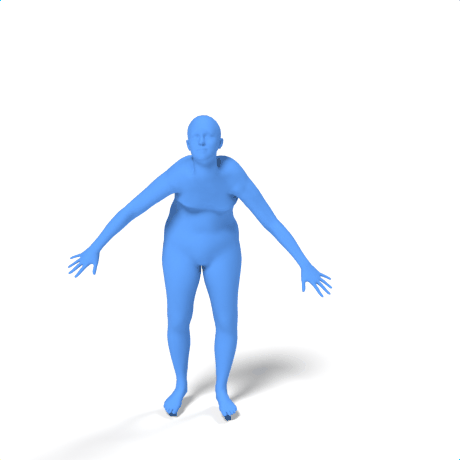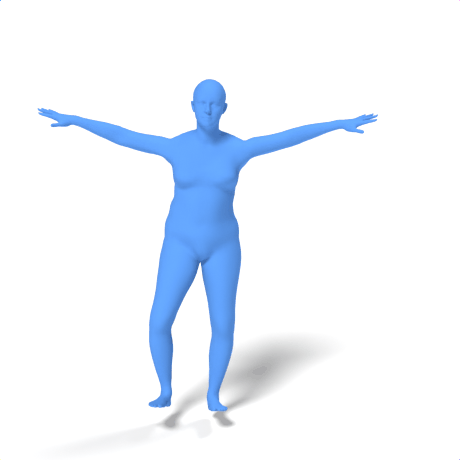
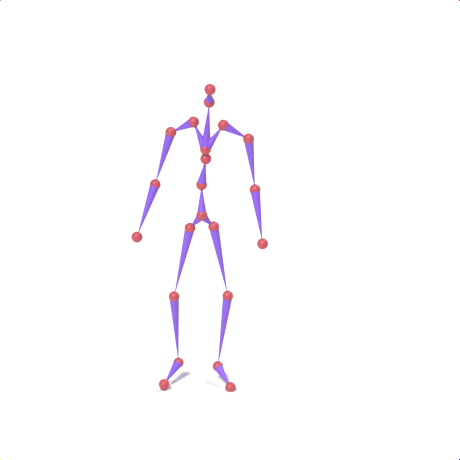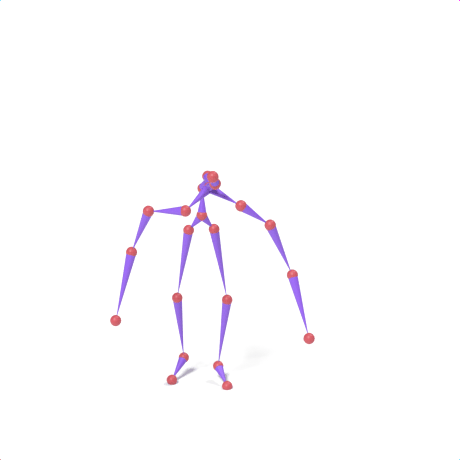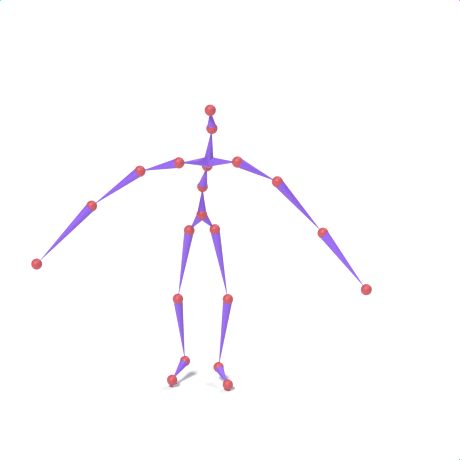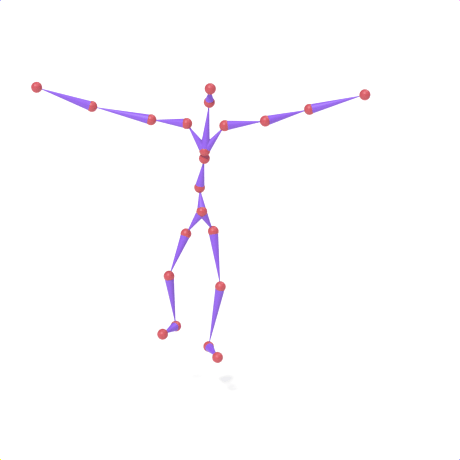

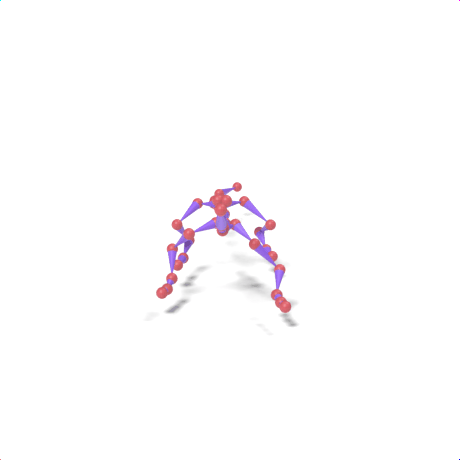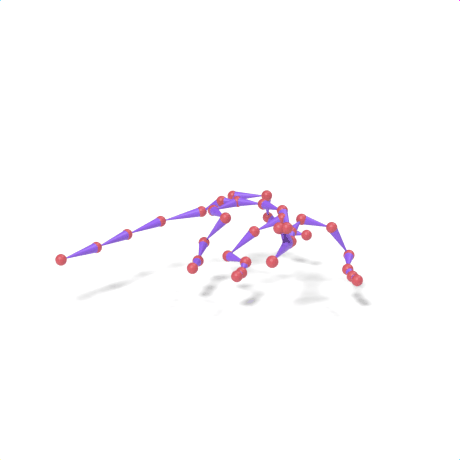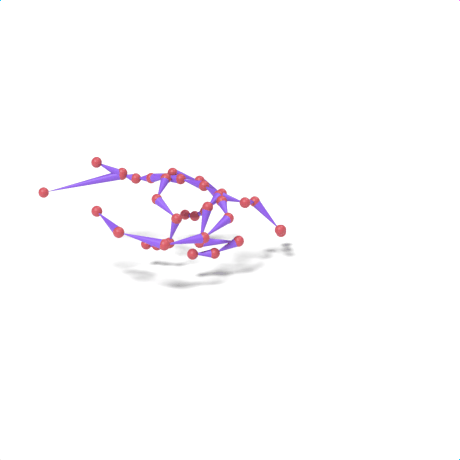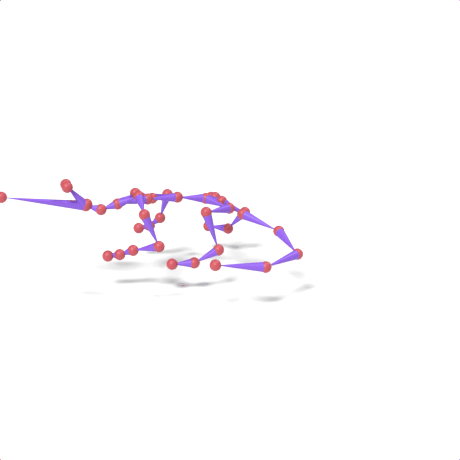

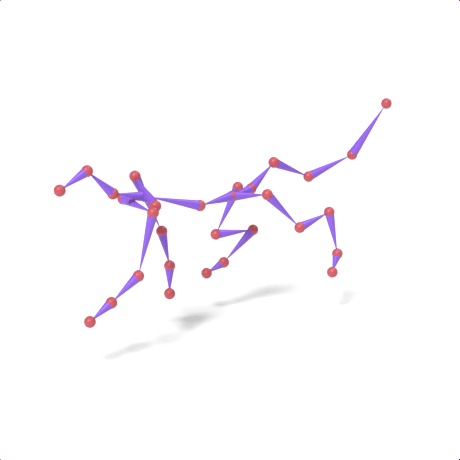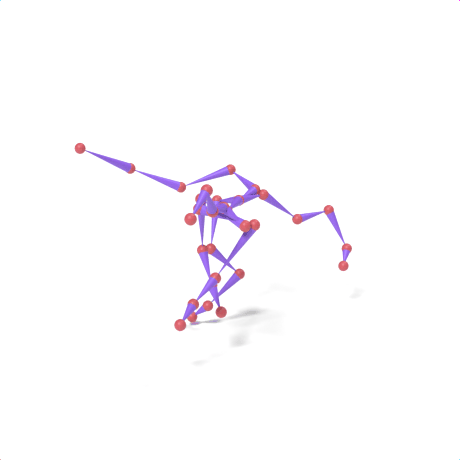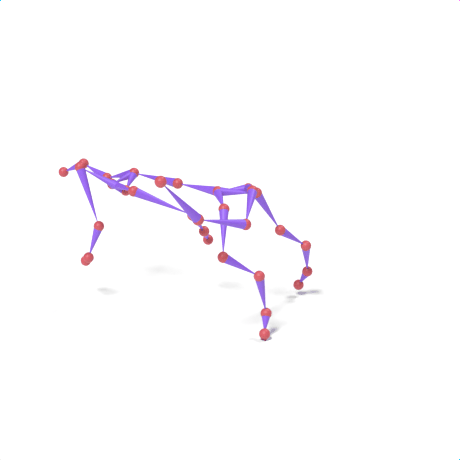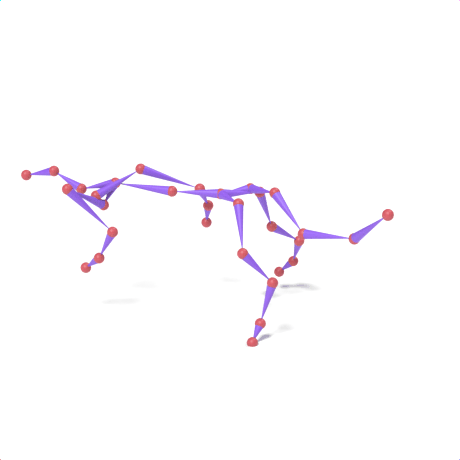
SAMoR part tokens are decoded from a text-conditioned MaskGIT generator and rendered on the target skeleton. Each card shows one character in a 2×2 grid: top row is the mesh (rest pose | generated motion via LBS), bottom row is the skeleton (rest | generated motion).


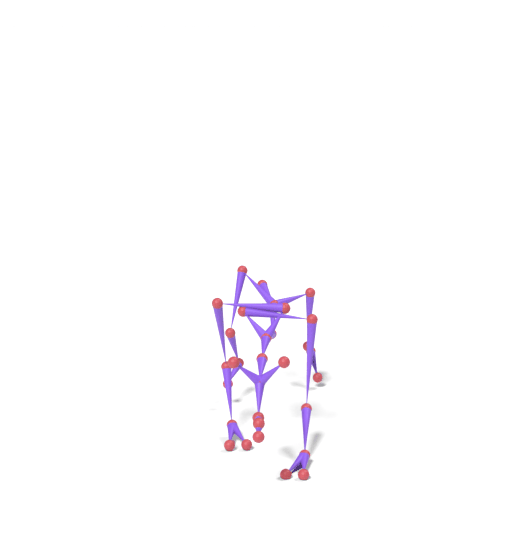



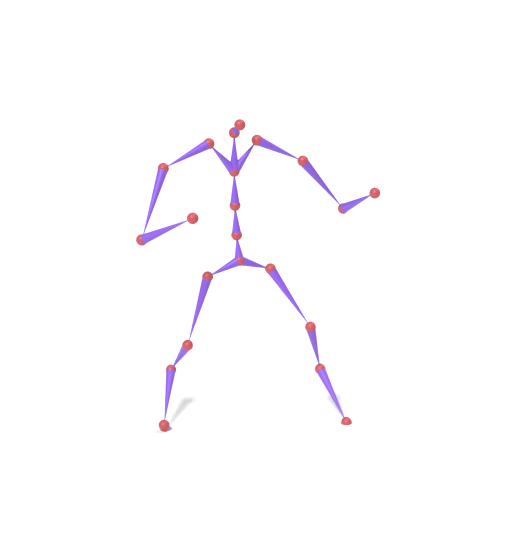
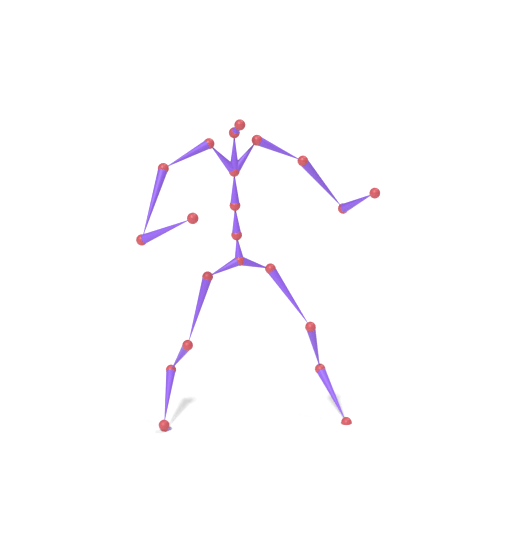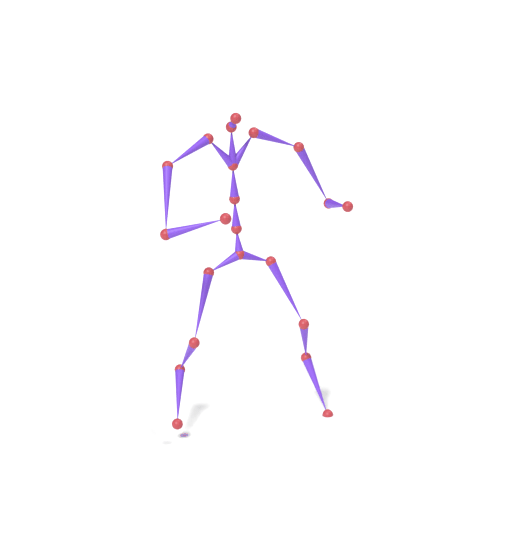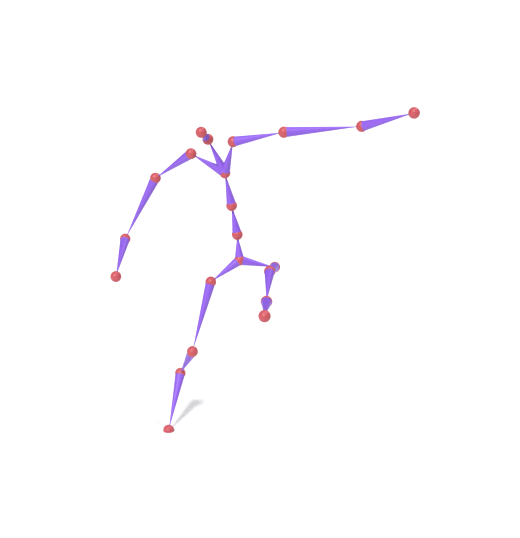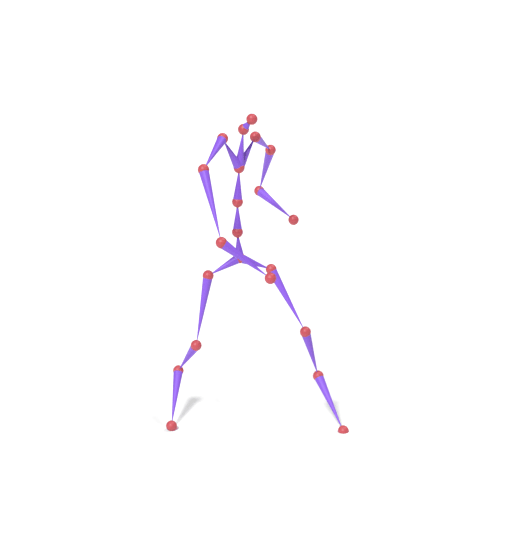
The original motion is encoded into SAMoR tokens. A subset of part slots (lower body) is masked and re-generated with a new prompt, while upper-body tokens remain fixed. Each column shows the skeleton motion on top and the LBS-driven textured mesh below.

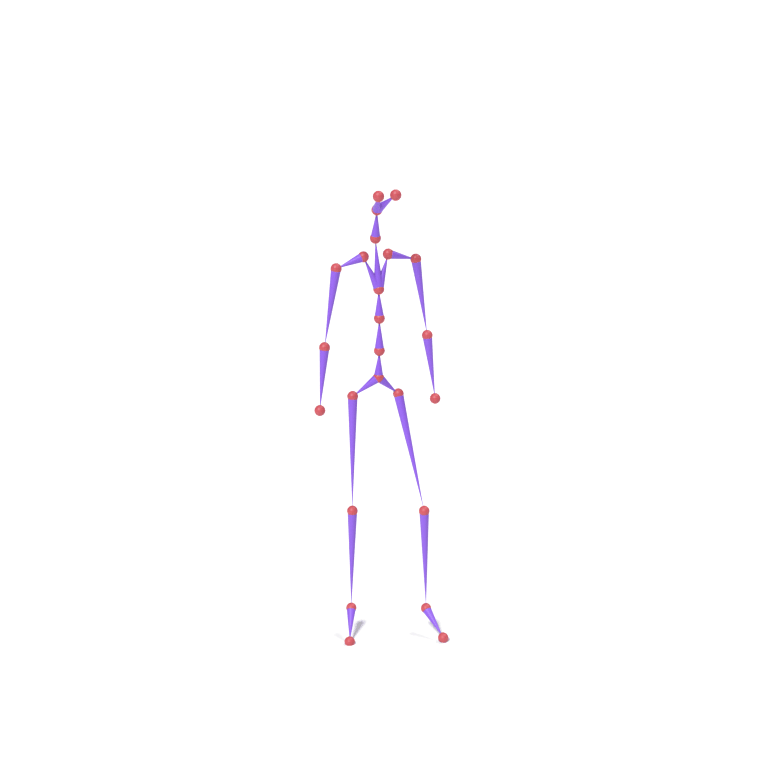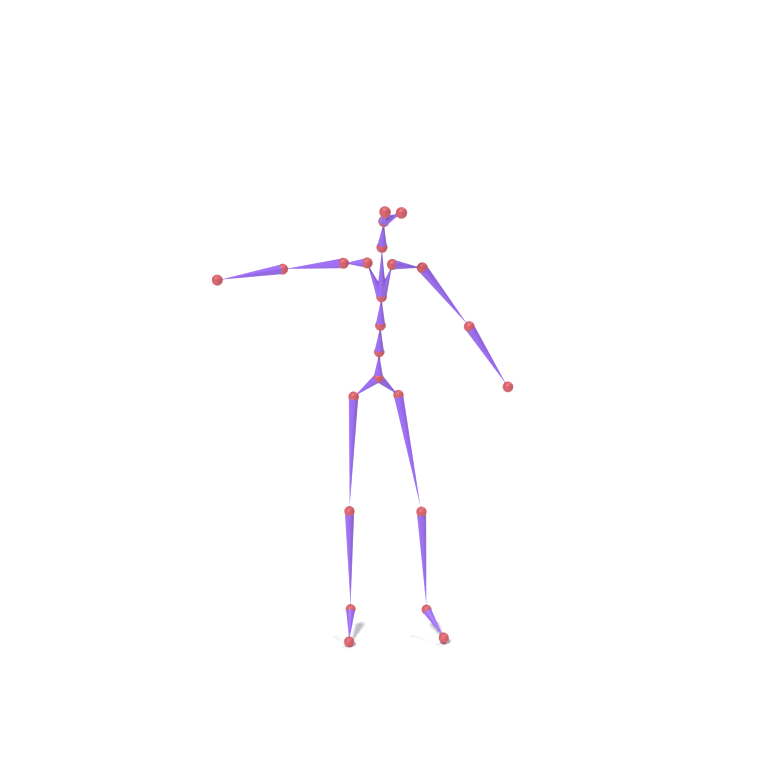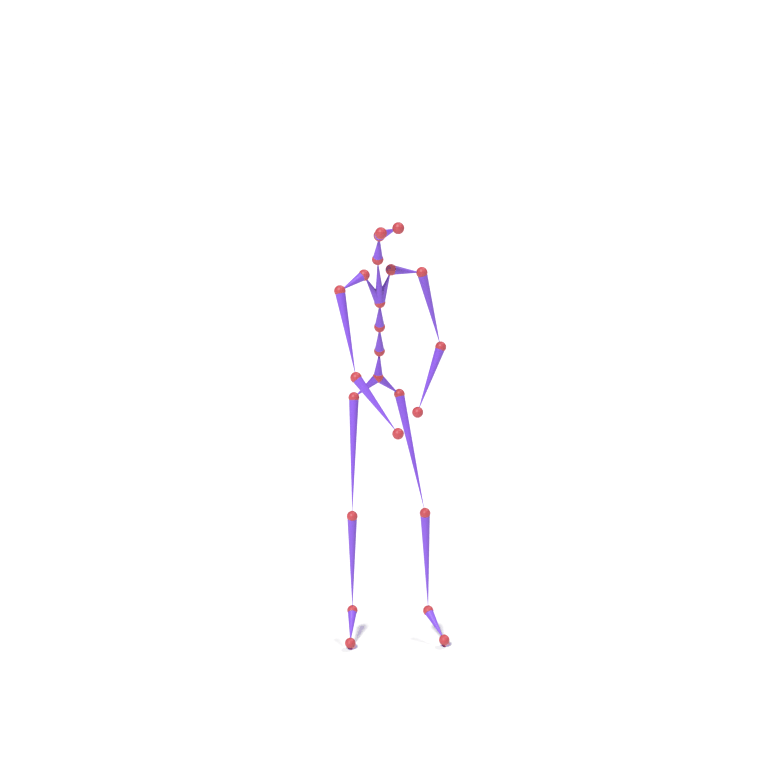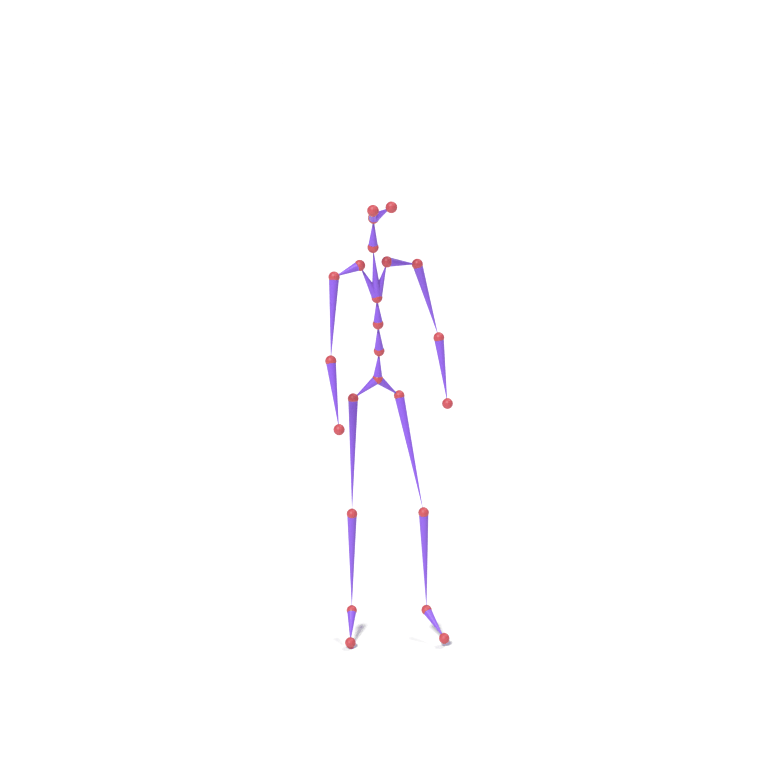

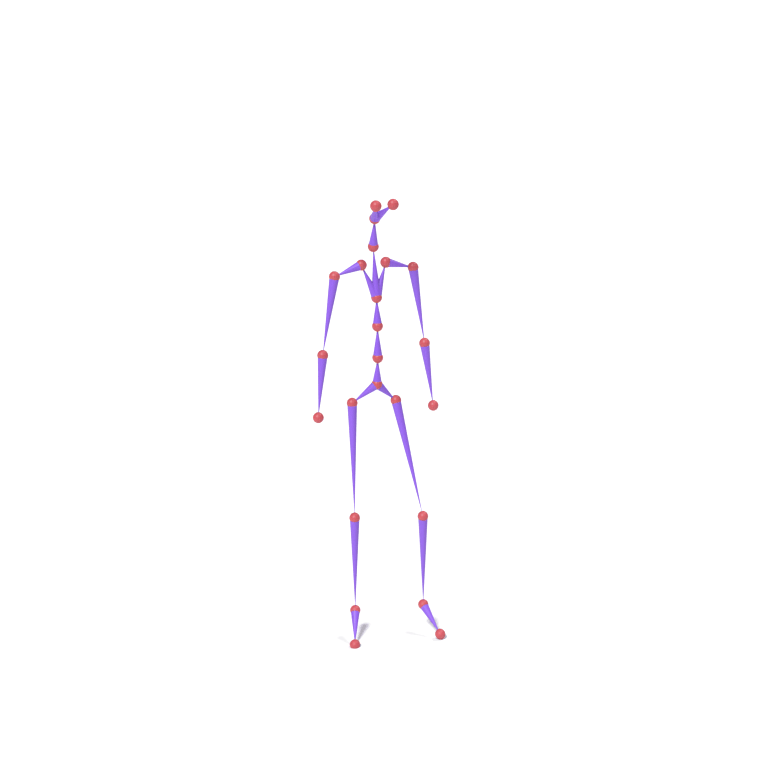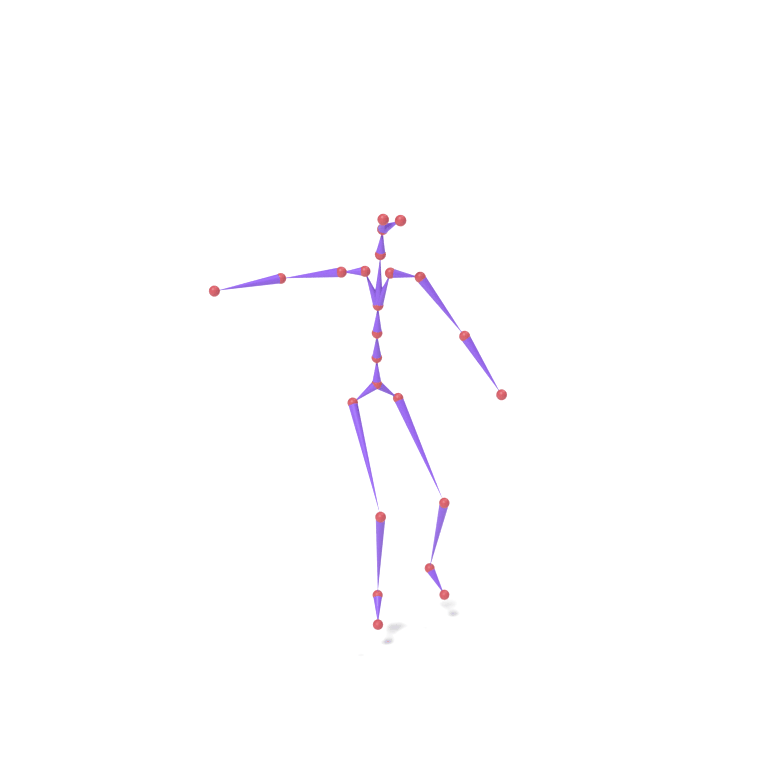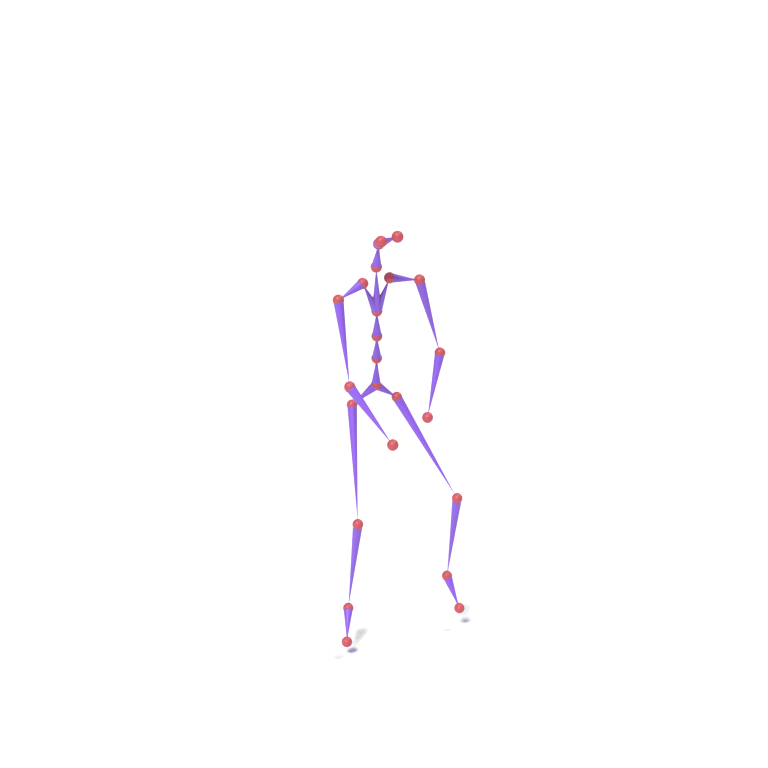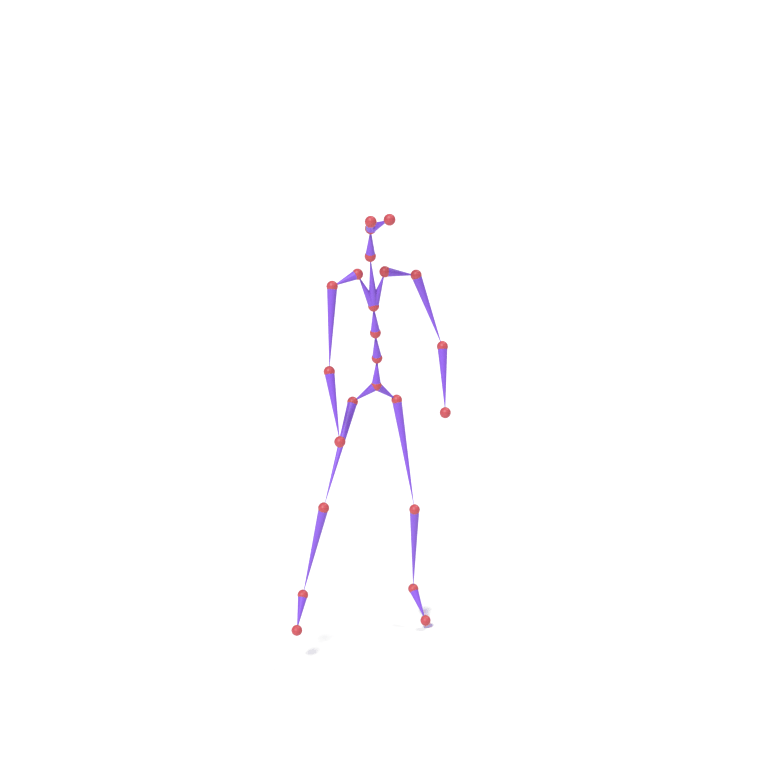
Lower-body part tokens from a human walking motion and upper-body part tokens from an eagle take-off motion are combined and decoded together on a chicken skeleton. The top card shows skeleton motions; the bottom card shows the corresponding LBS-driven textured meshes.




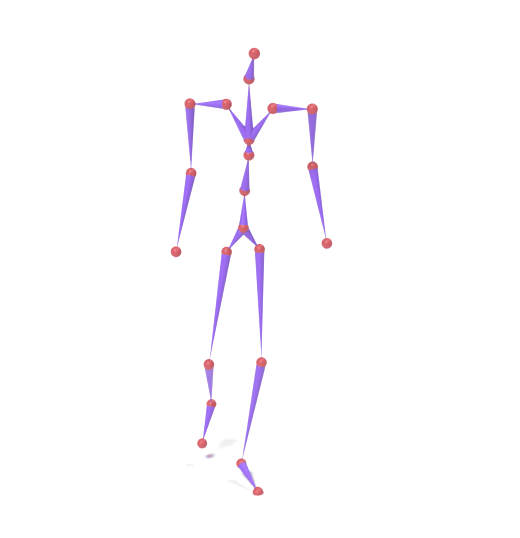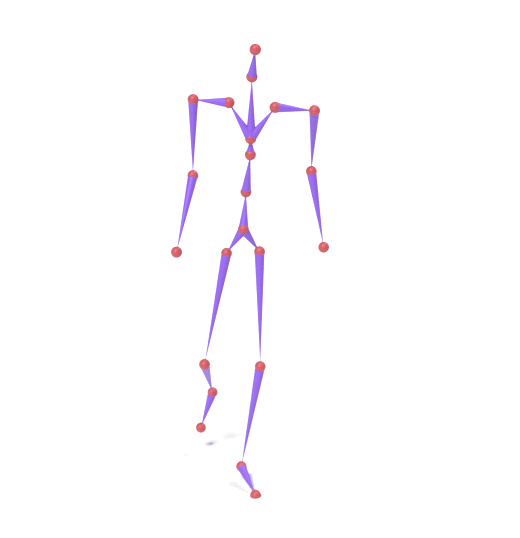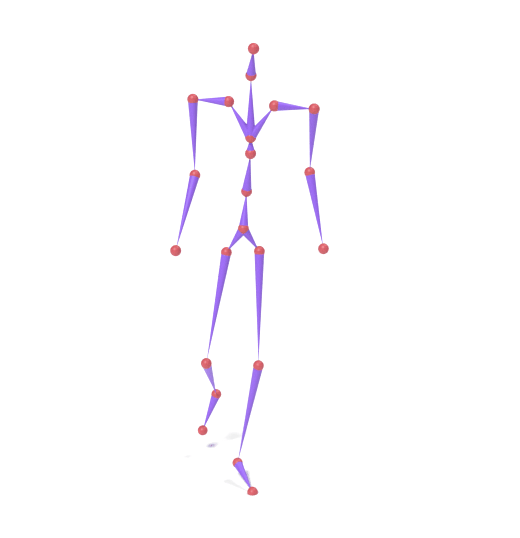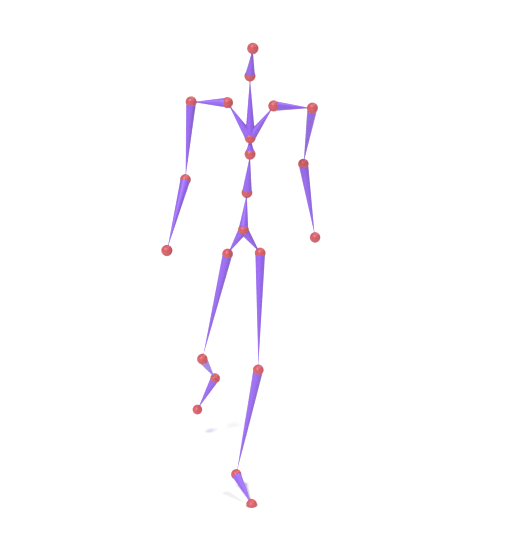

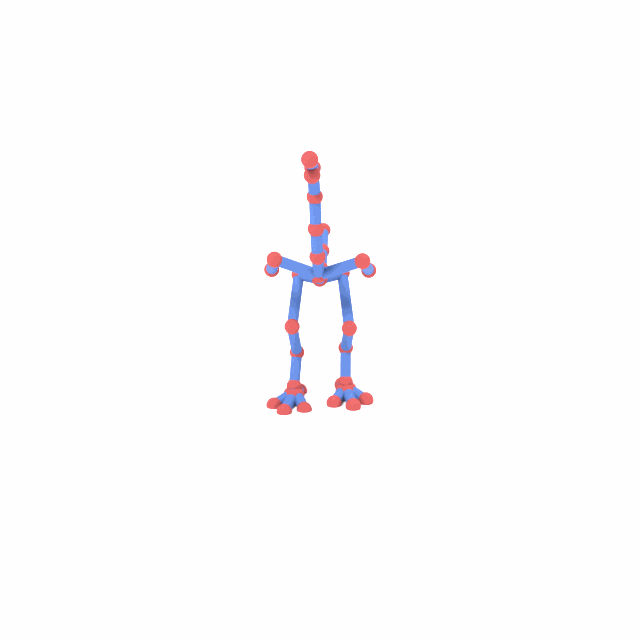

SAMoR operates on joint positions rather than rotations in the cross-topology setting, because heterogeneous assets lack a unified rest-pose reference that makes local rotations comparable across rigs. Recovering bone rotations for LBS mesh animation therefore requires an IK post-process, which introduces twist ambiguity; accurate twist recovery from positions alone remains an open problem.
The K = 8 functional grouping is a fixed design choice. Learning the number and structure of part groups automatically — adapting it to the topology of the target rig — is a natural direction for future work.
@misc{samor2026,
author = {TBD},
title = {TBD},
year = {TBD},
eprint = {TBD},
url = {TBD}
}